ANTLR 4 笔记
“语言的边界就是思想的边界。”
Getting Started with ANTLR v4 | GitHub
The Definitive ANTLR 4 Reference 英文版和示例代码
是什么
ANTLR 是:
语法分析器的生成器:可以根据一个程序设计语言的语法描述自动生成语法分析器。
扫描器的生成器:可以根据一个语言的语法单元的正则表达式描述生成词法分析器。
语法制导的翻译引擎:ANTLR 会生成语法树并生成相应的访问器或者监听器类来遍历语法树。
使用 LL(*) 文法的解析器。
包含很多现成的语法定义,解析主流的语言都可以开箱即用:antlr/grammars-v4 · GitHub。
安装
命令行
https://www.antlr.org/download/
1 | CLASSPATH =.;D:\javalib\*; |
1 | :: antlr4.bat |
1 | ::grun.bat |
IDEA
- 安装插件 ANTLR v4 grammar plugin
- 在语法文件的规则上 右键 -> Test Rule ... ,来实时测试语法树
- 在语法文件里面 右键 -> Generate ANTLR Recognizer 来生成代码
VS Code
安装插件 ANTLR4 grammar syntax support。
Hello world
1 | // Define a grammar called Hello |
1 | grun Hello r -gui |
退出:Windows 按下 Ctrl + Z,Enter 退出。
遍历语法树
ANTLR 的监听器和访问器能够将语法和程序逻辑代码解耦,可以不需要在语法中内嵌动作。
使用访问器和监听器机制,我们可以完成一切与语法相关的事情。一旦进入Java的领域,就没有什么ANTLR的相关内容值得学习了。我们需要谨记在心的是,语法及其对应的语法分析树,以及访问器或者监听器事件方法之间的关系。除此之外,剩下的仅仅是普通的代码。在对输入文本进行识别时,我们可以产生输出、收集信息(正如本例中我们所做的)、用某种方式验证输入文本,或者执行计算。
Listener(监听器)
类似于 XML 的 SAX 解析。监听器的方法会被 Antlr 提供的遍历器对象自动调用。
可以用 ParseTreeProperty 来储存和获取变量。
1 | ParseTreeProperty<Integer> values = new ParseTreeProperty<Integer>(); |
Visitor(访问器)
访问器方法中,需要显式地调用 visit() 方法来访问子节点,可以自己定义怎么访问子树。
代码生成
- Parser.java
- Lexer.java
- .tokens
- Listener.java
入门
语法导入
使用 import 可以让语法文件模块化。
标签
1 | stat: expr NEWLINE # printExpr |
加了标签的备选分支,会生成相应的访问器方法。
语法分析
语法中嵌入动作
使用语义判定改变语法分析过程
词法分析
孤岛语法。例子:解析xml
重写输入流。例子:java代码添加序列化标识符
将词法送入不同通道。例子:忽略却保留注释和空白字符
开发
设计语法
起始规则,词法符号,语法规范
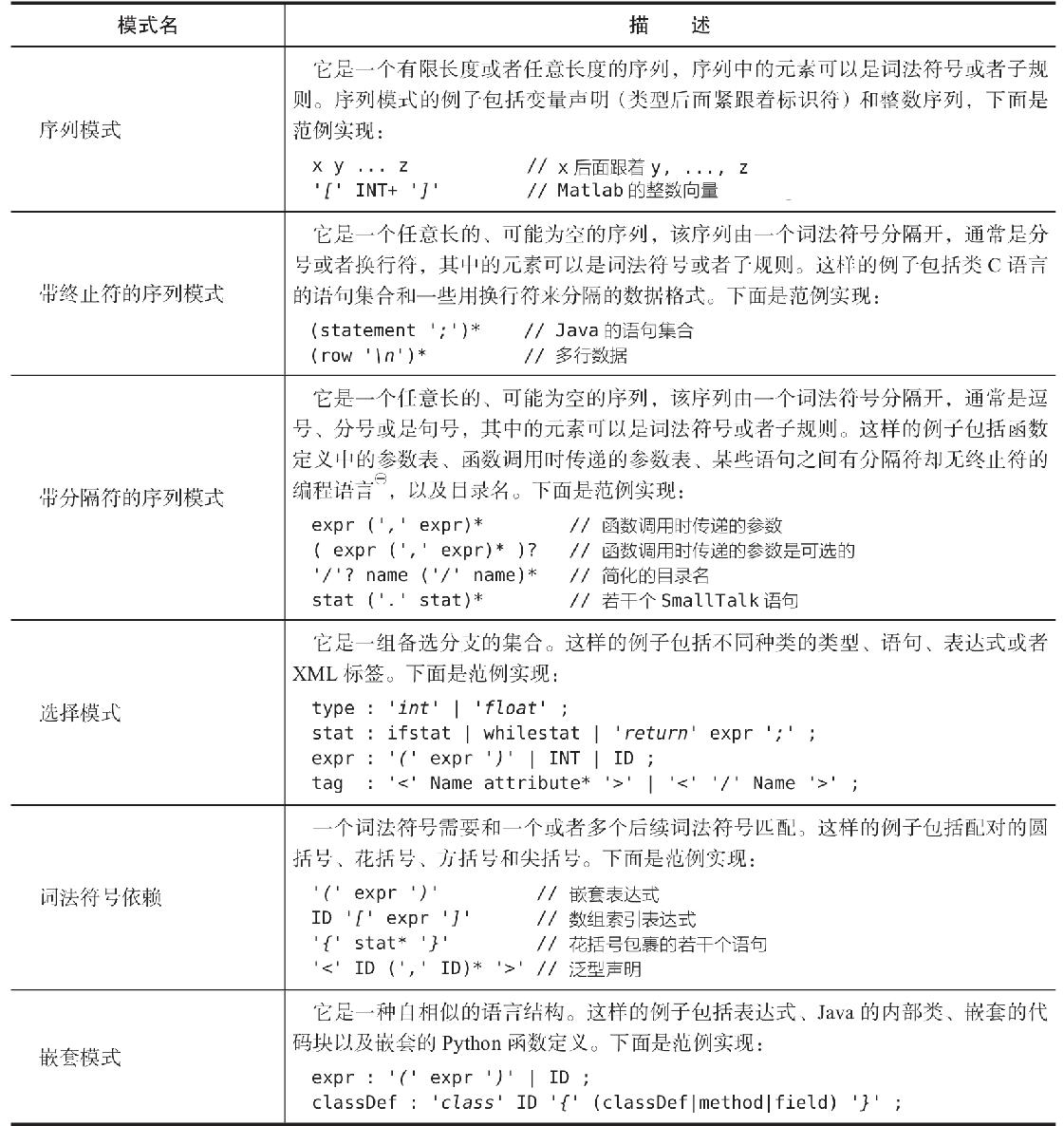
常见的语言模式
- 序列(sequence)
- 选择(choice)
- 词法符号依赖(token dependency)
- 嵌套结构(nested phrase)
序列模式
比如一个协议语言POP,由关键字、整数和换行组成。
1 | retr : 'RETR' INT '\n' |
任意长度序列可以用 + 字符。(INT)+ 或者
INT+。
可以为空,零个或多个用 *。
零个或一个:?。
选择模式(多个备选分支)
使用符号 |
作为“或者”来表达编程语言中的选择模式。备选分支(alternative)或者可生成的结果(productions)。
1 | type : 'float' | 'int' | 'void' |
词法符号依赖模式
依赖符号的语法,比如数组的括号。表达对符号的依赖的方法。
1 | vector : '[' INT+ ']' ; // [1], [1 2], [1 2 3], ... |
嵌套模式
自己引用自己。如果一条规则定义中的伪代码引用了它自身,就需要一条递归规则(自引用规则)。
直接递归和间接递归。
1 | expr : ID '[' expr ']' |
左递归和优先级
经典的从左到右自顶向下的语法分析器无法处理左递归。算符优先级带来的问题。ANTLR解决的方式是,写在前面的语法拥有较高的优先级。如果遇到了从右向左结合的,需要使用 assoc 手工指定结合性:
1 | expr : <assoc=right> expr '^' expr |
ANTLR 4 可以能够处理直接左递归,但是不能处理间接左递归。
识别词法
匹配标识符
1 | ID : ('a'..'z'|'A'..'Z')+ ; //匹配1个或多个大小写字母 |
或者:
1 | ID : [a-zA-z]+ ; |
ID 规则可能和其他规则冲突,比如其他关键字 enum 或 for。所以要把 ID 规则放在所有关键字规则之后。
匹配数字
1 | INT : '0'..'9'+ ; |
或者
1 | INT : [0-9]+ ; |
浮点数:
1 | FLOAT : DIGIT+ '.' DIGIT* // 1. 3.14 |
将一条规则声明为 fragment 可以告诉ANTLR,该规则本身不是一个词法符号,它只会被其他的词法规则使用。
字符串
1 | STRING : '"' .*? '"' ; |
. 匹配任意单个字符,.*
匹配零个或多个,? 标记表示使用非贪婪匹配子规则(nongreedy
subrule)。
转义字符:
1 | STRING : '"' (ESC|.)*? '"' ; |
注释和空白字符
C 中的单行和多行注释:
1 | LINE_COMINT : '//' .*? '\r'? '\n' -> skip ; // 消费掉双斜杠后面的一切字符,直到遇到换行符 |
空白字符:
1 | WS : [ \t\r\n]+ -> skip ; |

解析现成的语言
要想揭开一门语言的神秘面纱,我们需要分析不同来源的信息。语言的规模越大,我们需要的参考文档和各式各样的范例代码就越多。有时候,只有设法对语言现有的实现进行试探,才能发现边界情况。语言的参考文档通常并非一目了然。
- CSV
- JSON
- DOT
- Cymbol
语法和程序逻辑
在事件方法中共享信息
使用访问器的方法来返回值
继承 BasicVisitor 的时候指定泛型
使用类的成员在事件方法之间共享数据
比如在监听器的类中声明一个栈,每个子表达式的结果退入栈中,然后在更高层的节点中取出来。
对语法分析树的结点进行标注
可以直接将语句绑定在语法上,这样每一个节点都会有这个值:
e returns [int value] ...;。使用
ParseTreeProperty的辅助类,本质上是 IdentityHashMap,用节点对象作为键。
高级特性
上下文相关的词法问题
(12章第二节)
因为ANTLR自动生成的语法分析器经常在词法符号流中进行非常远的前瞻以作出语法分析决策。这意味着,远在语法分析器能够执行提供上下文信息的行为之前,词法分析器就需要将字符流处理为词法符号。
因为这样,处理上下文相关的词法问题变得比较困难。
关键字作为标识符的问题的解决方法是,令词法分析器将所有关键字当作词法符号送给语法分析器。